[1] 49.94695Resúmenes gráficos
Ingeniería de Datos Aplicado a la Estadística, PEUCD 2025
2025-08-12
Gráficos de barras
Gráficos de barras

Gráficos de barras apiladas
Gráficos de barras agrupadas

Gráficos de barras horizontales
Gráficos de barras horizontales

Gráficos de barras horizontales apiladas
Gráficos de barras horizontales apiladas

Gráficos de barras flechas horizontales
Gráficos de pastel

Gráficos de donas

Gráficos de donas

Gráficos de voronoi

Gráficos de voronoi

Gráficos de ¿voronoi?

Gráficos de mapa de árboles

Gráficos de mapa de árboles

Gráficos de mapa de árboles

PS: Probablemente una mala opción para un comparativo
Gráficos de líneas

Gráficos de líneas

Gráficos de líneas

Gráficos de múltiples líneas

Gráficos de múltiples líneas

Gráficos de múltiples líneas

Gráficos de líneas barras

Gráficos de líneas y áreas

Gráficos de áreas

Gráficos de áreas

Gráficos de áreas

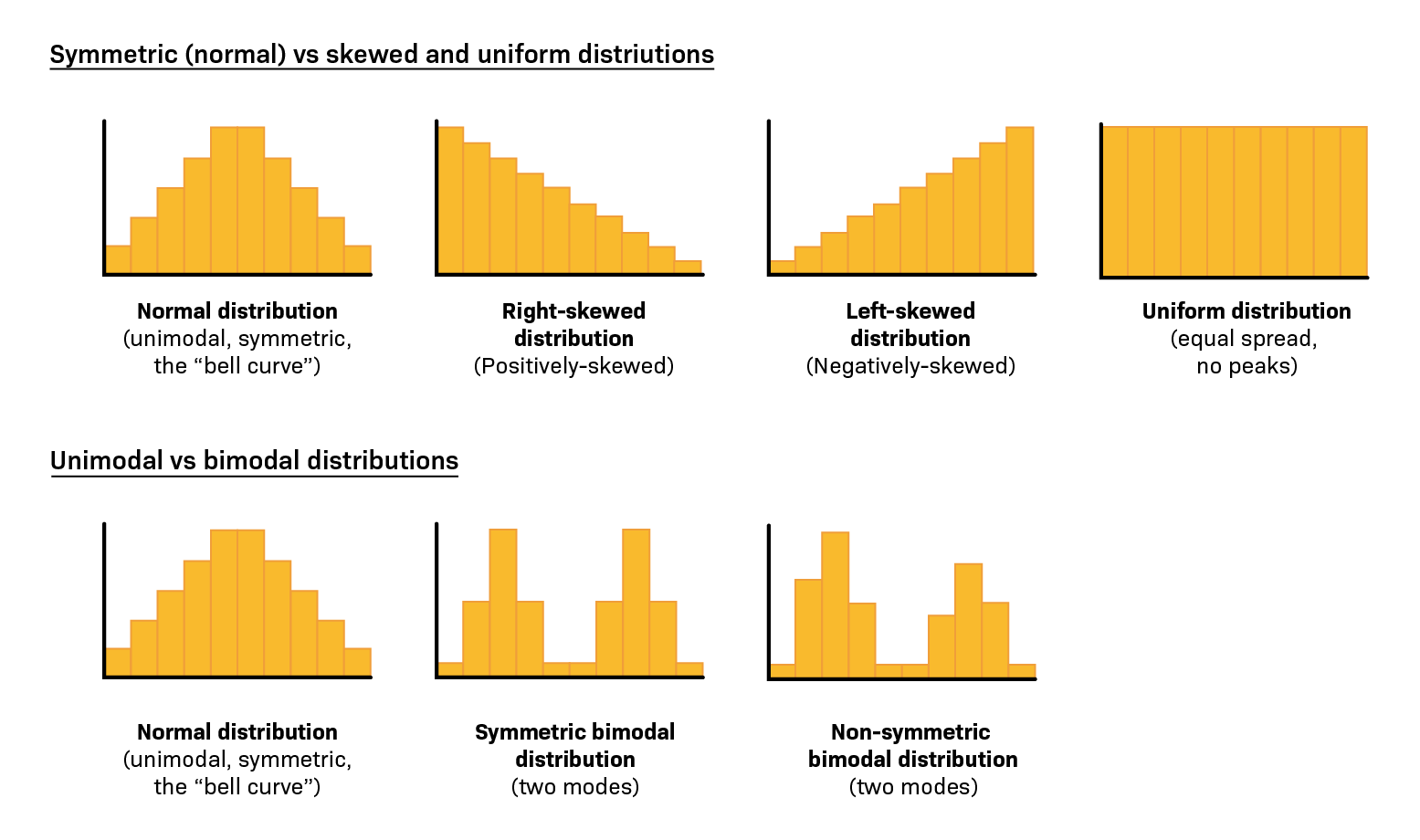
Histograma y tipos de distribuciones
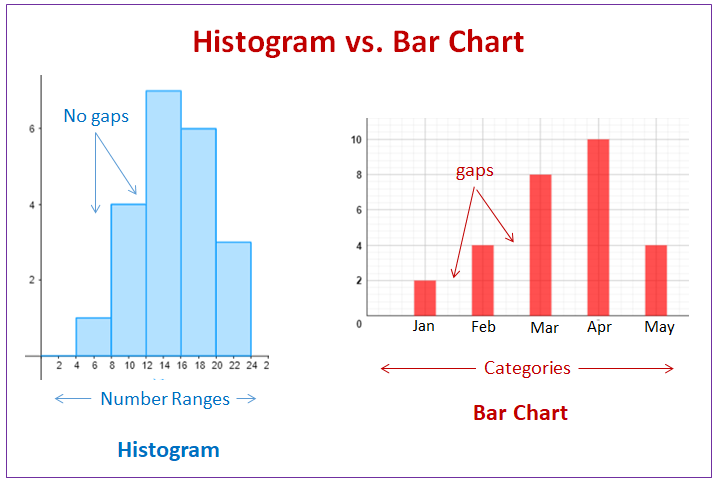
Histograma vs Barras
Histograma

Histograma

Histograma

Histograma

Elección del número de intervalos (bins)

Elección del número de intervalos (bins): comparativo

¿Histogramas en las cámaras?

Boxplot
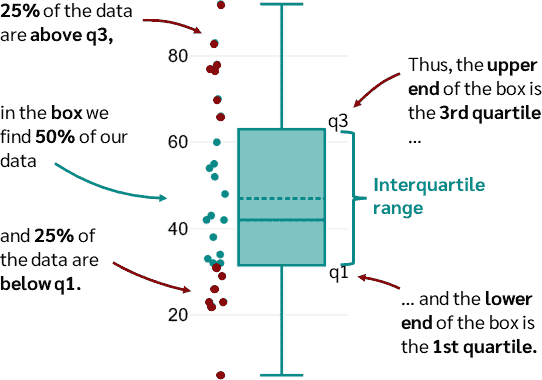
Boxplot: Mediana o Q2
La mediana es el valor central que divide la serie de datos en dos partes iguales. En el boxplot, se representa como una línea dentro de la caja.

Boxplot: RIQ (IQR)
El IQR muestra la distancia o diferencia entre el tercer cuartil (Q3) y el primer cuartil (Q1), y representa el rango donde se encuentra el 50% central de los datos, mostrando la dispersión de la distribución. Para calcularlo usaremos quantile().
Q1: 43.26553 Q3: 56.78582 IQR: 13.5203 
Boxplot: Bigotes
Los bigotes muestran los valores más alejados del centro que no son considerados outliers. Los bigotes representan los rangos del 25 % de valores de datos de la parte inferior y el 25 % de la parte inferior.

Boxplot: Cuartiles (Q1 y Q3)
El primer cuartil (Q1) es el valor por debajo del cual se encuentra el 25% de los datos, mientras que el tercer cuartil (Q3) es el valor por debajo del cual se encuentra el 75% de los datos. Estos definen los bordes de la caja en el boxplot.

Boxplot con outliers
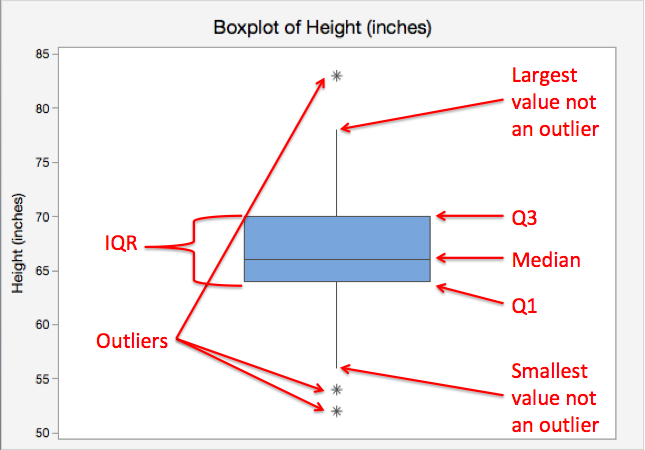
Boxplot: Outliers
Los outliers son puntos fuera de los bigotes y se consideran valores anómalos. Son útiles para identificar variaciones extremas en los datos.

Boxplot: Resumen
Los outliers son puntos fuera de los bigotes y se consideran valores anómalos. Son útiles para identificar variaciones extremas en los datos.
