Tipo Tipo_enconded
1 Manzana Manzana
2 Pera Pera
3 Banana Banana
4 Manzana Manzana
5 Uva Otros
6 Manzana Manzana
7 Pera Pera
8 Melón Otros
9 Banana Banana
10 Pera Pera
11 Melón OtrosTransformaciones básicas
Ingeniería de Datos Aplicado a la Estadística, PEUCD 2025
Víctor Fuentes Campos
2025-08-14
Transformaciones de variables categóricas
Agrupamiento o reducción de niveles
El agrupamiento de niveles de una variable categórica consiste en reducir o re-clasificar las categorías originales para simplificar el análisis. Esto puede hacerse fusionando categorías similares o según criterios específicos, como el precio promedio, frecuencia o características relevantes, facilitando la interpretación de datos complejos y evitando el sobreajuste en modelos estadísticos o de machine learning.
Agrupamiento o reducción de niveles
Agrupamiento o reducción de niveles

Técnicas de reducción
Las técnicas de reducción de categorías buscan optimizar variables categóricas con muchos niveles, facilitando el análisis y mejorando la eficiencia en modelos. Entre las principales estrategias se encuentran:
- Fusión por frecuencia: Agrupar categorías con baja ocurrencia en un nivel común (como “Otros”).
- Agrupación basada en significado: Combinar niveles con similitudes semánticas o funcionales.
- Agrupamiento jerárquico: Crear niveles más amplios a partir de jerarquías o clasificaciones predefinidas.
Clasificación jerárquica
Se emplea para organizar y categorizar datos cualitativos de manera estructurada. Se basa en la jerarquización de categorías según sus características, relevancia, u otros criterios para simplificar el análisis y facilitar la interpretación.
Clasificación jerárquica
# Crear un dataset de ejemplo
datos <- data.frame(
producto = c("Laptop", "Televisor", "Refrigerador", "Lavadora", "Laptop",
"Tablet", "Microondas", "Televisor", "Refrigerador", "Celular",
"Laptop", "Tablet", "Lavadora", "Microondas", "Celular",
"Laptop", "Microondas", "Televisor", "Celular", "Refrigerador")
)
electrodom <- c("Televisor", "Refrigerador", "Lavadora", "Microondas")
electronic <- c("Laptop", "Tablet", "Celular")Clasificación jerárquica
Clasificación jerárquica
producto categoria
1 Laptop Dispositivos Electrónicos
2 Televisor Electrodomésticos
3 Refrigerador Electrodomésticos
4 Lavadora Electrodomésticos
5 Laptop Dispositivos Electrónicos
6 Tablet Dispositivos Electrónicos
7 Microondas Electrodomésticos
8 Televisor Electrodomésticos
9 Refrigerador Electrodomésticos
10 Celular Dispositivos Electrónicos
11 Laptop Dispositivos Electrónicos
12 Tablet Dispositivos Electrónicos
13 Lavadora Electrodomésticos
14 Microondas Electrodomésticos
15 Celular Dispositivos Electrónicos
16 Laptop Dispositivos Electrónicos
17 Microondas Electrodomésticos
18 Televisor Electrodomésticos
19 Celular Dispositivos Electrónicos
20 Refrigerador ElectrodomésticosLabel encoding
Asigna valores numéricos a las diferentes categorías de una variable categórica. Sin embargo, presenta una limitación importante, y es que estos valores numéricos pueden ser malinterpretados por algunos algoritmos de aprendizaje automático
Label encoding

Label encoding
Label encoding
#install.packages("CatEncoders")
library(CatEncoders)
## Ciudades
df <- data.frame(Ciudad =
c("Lima", "Cusco", "Arequipa", "Trujillo", "Lima", "Cusco"))
labs = LabelEncoder.fit(df$Ciudad)
# Aplicar Label Encoding
df$Ciudad_encoded = transform(labs, df$Ciudad)
print(df) Ciudad Ciudad_encoded
1 Lima 3
2 Cusco 2
3 Arequipa 1
4 Trujillo 4
5 Lima 3
6 Cusco 2One-hot encoding
Transforma una variable categórica en varias columnas binarias. Cada columna representa una categoría y contiene un 1 si esa categoría está presente, o un 0 en caso contrario. Se utiliza principalmente para variables nominales (categorías sin un orden lógico). Por ejemplo, colores o tipos de productos.
One-hot encoding
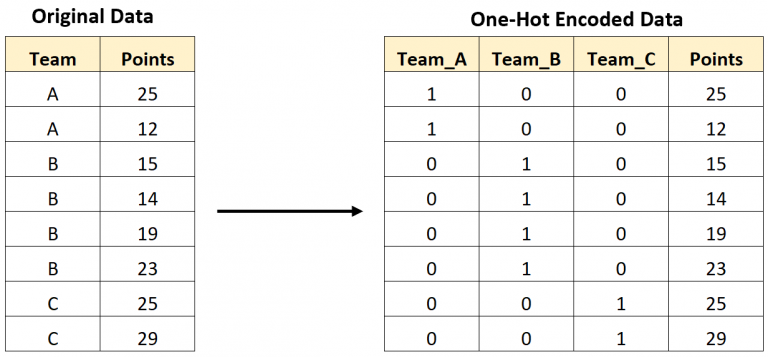
One-hot encoding
One-hot encoding
# Crear columnas binarias (One-Hot Encoding)
for (cat in categorias) {
df[paste("Producto", cat, sep = "_")] <- ifelse(df$Producto == cat, 1, 0)
}
print(df) Producto Producto_A Producto_B Producto_C
1 A 1 0 0
2 B 0 1 0
3 A 1 0 0
4 C 0 0 1
5 B 0 1 0
6 C 0 0 1
7 A 1 0 0
8 C 0 0 1
9 B 0 1 0
10 C 0 0 1
11 B 0 1 0
12 A 1 0 0One-hot encoding: ventajas
Al representar una variable categórica con diferentes columnas binarias, cada valor único de la categoría se convierte en una variable independiente. Esto facilita la interpretación de los resultados del modelo, sobre todo en técnicas como la regresión lineal o árboles de decisión.
Una alternativa al One-Hot Encoding es el label encoding. Sin embargo, los modelos pueden suponer una relación de orden. El One-Hot Encoding elimina esta posibilidad, ya que representa las categorías de manera no ordinal.
Label Encoding vs One-hot encoding
| Aspecto | Label Encoding | One-Hot Encoding |
|---|---|---|
| Cuándo usar | • Variables ordinales (orden lógico claro) • Modelos basados en árboles (p. ej. árboles de decisión, Random Forest) |
• Variables nominales (sin orden implícito) • Modelos lineales (p. ej. regresión logística) |
| Ventajas | • Eficiente, no incrementa dimensionalidad • Ideal para modelos no sensibles a magnitud numérica |
• No introduce relaciones numéricas erróneas • Seguro para modelos sensibles a la magnitud |
| Desventajas | • Orden falso en variables nominales • Puede inducir jerarquías inexistentes |
• Alta dimensionalidad si hay muchas categorías • Riesgo de sobreajuste en datasets pequeños |
Transformaciones de variables numéricas
Logaritmos
- Esta transformación se utiliza, por ejemplo, cuando los datos presentan una distribución sesgada hacia la derecha (asimetría positiva).
- La transformación logarítmica reduce la asimetría y puede facilitar la interpretación de los datos.
Logaritmos

Ojo con las marcas del eje X
Logaritmos

Logaritmos
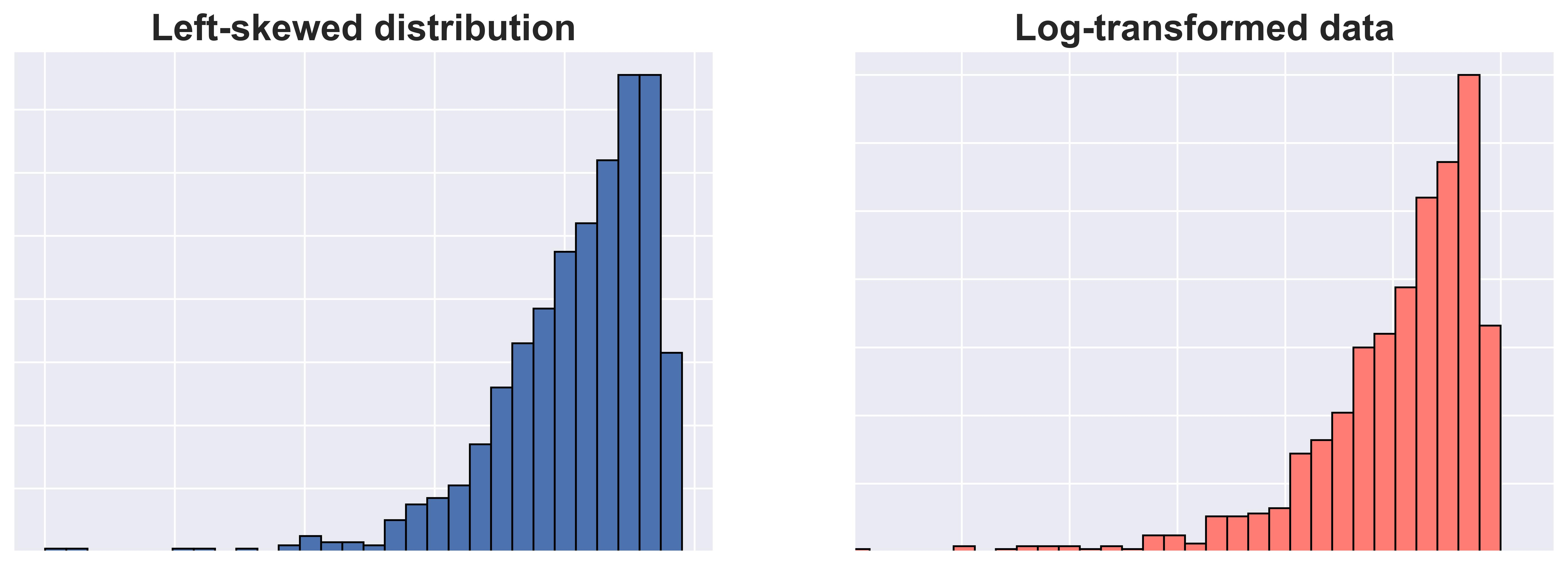
La transformación logarítmica no corrige distribuciones con sesgo a la izquierda.
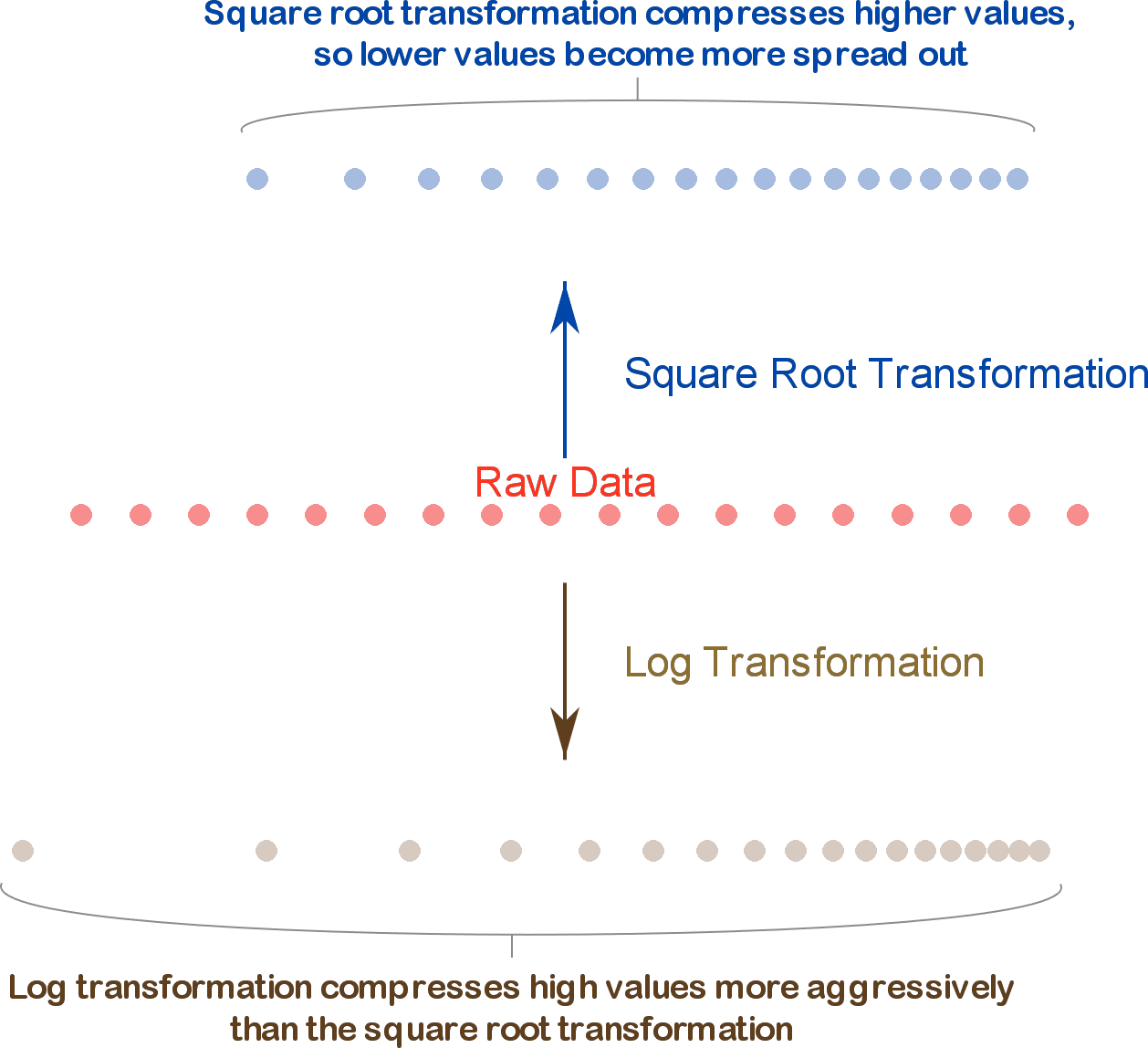
Raíz cuadrada
- Una transformación de raíz cuadrada se utiliza principalmente para reducir la asimetría y estabilizar la varianza en los datos.
- Es particularmente útil cuando se tiene una distribución con valores altos o outliers que generan una distribución sesgada, pero menos severa que la que justifica una transformación logarítmica.
Raíz cuadrada

Raíz cuadrada

Logaritmos vs. Raíz cuadrada
Escalado: normalización
- Escalado de los valores de las características entre un rango específico (por ejemplo, entre 0 y 10).
- Se utiliza cuando los datos no siguen una distribución normal.
- El objetivo es que todas las variables contribuyan de manera equitativa al análisis o modelo, especialmente cuando estas tienen diferentes unidades o escalas.
Escalado: normalización
Escalado: normalización por Min-Max
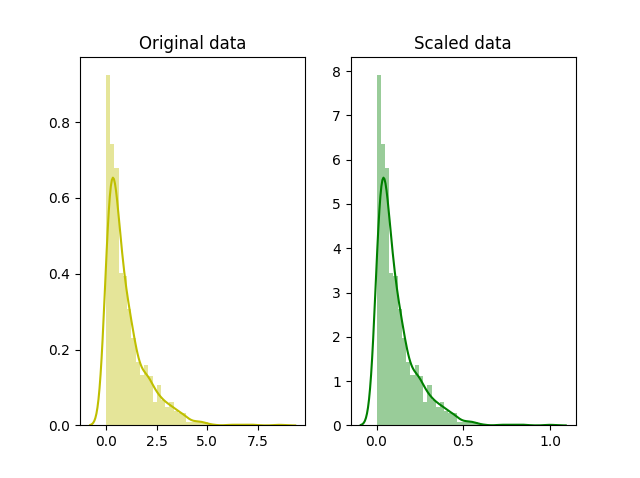
- El escalado Min-Max convierte los valores de las variables a un rango específico, generalmente entre 0 y 1 ó -1 y 1.
- Esto ayuda a mejorar la estabilidad de los algoritmos sensibles a la escala, mientras que se mantiene las distencias relativas de los valores de la distribución.
Escalado: normalización por Min-Max

Escalado: normalización por Min-Max
Escalado: estandarización
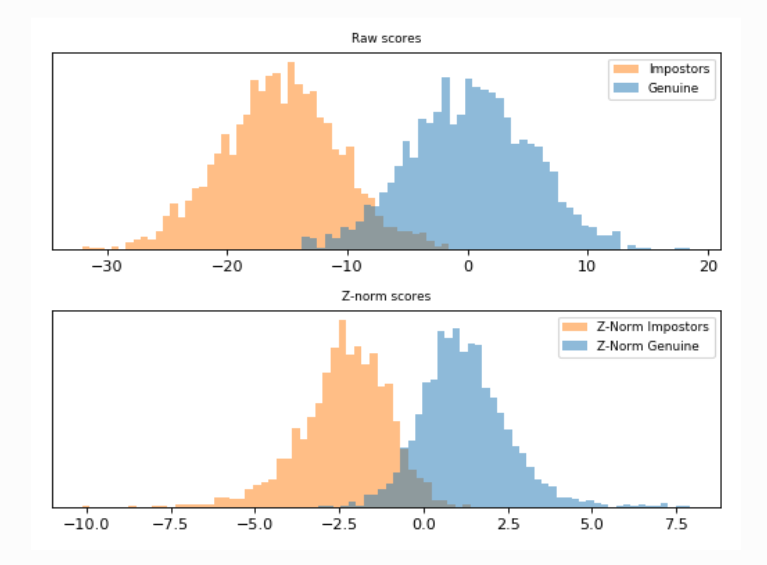
- Mientras que la normalización escala las características a un rango específico, la estandarización (o z-score scaling) transforma los datos para que tengan una media de 0 y una desviación estándar de 1.
- Se usa cuando los datos tienen outliers significativos o se requiere que los datos sigan una distribución normal para ciertos métodos estadísticos, como modelos lineales o métodos de reducción de dimensionalidad como PCA. \[X_{std}=\frac{X-\mu}{\sigma}\]
Escalado: estandarización

Escalado: estandarización
Escalado: estandarización

Escalado: ¿por qué estandarizar?
Comparabilidad: Permite comparar variables que originalmente tienen diferentes unidades o escalas. Mejora del rendimiento de modelos: Algoritmos como regresión logística, SVM, K-means y PCA funcionan mejor con datos estandarizados.
Reducción del impacto de outliers: Al centrar y escalar los datos, se mitiga la influencia de valores atípicos.
Convergencia más rápida : Facilita la optimización en algoritmos de aprendizaje automático.
Discretización de variables contínuas
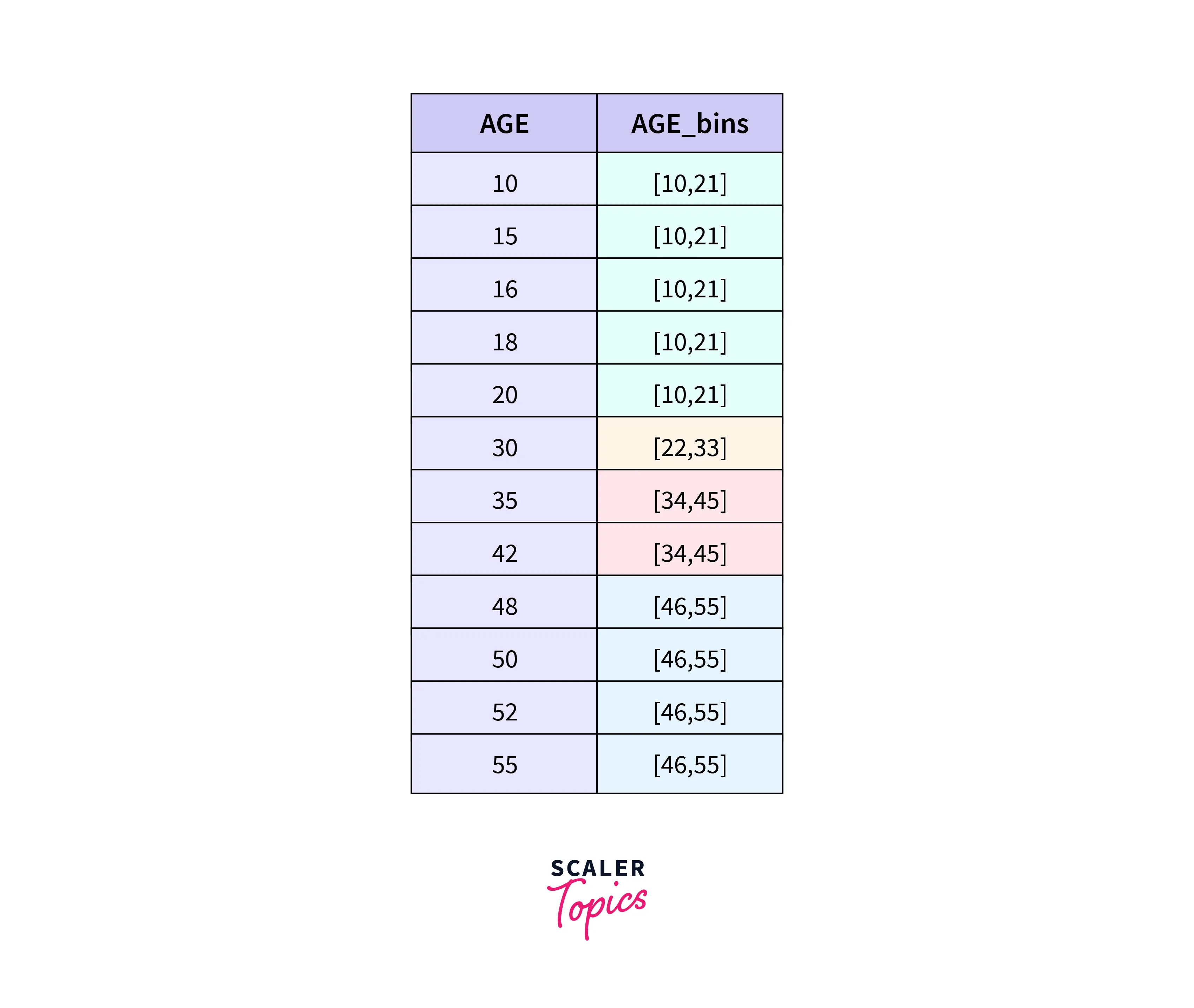
- Transforma variables continuas en variables categóricas o discretas al dividir el rango de valores de una variable continua en intervalos o “bins” y asignando una etiqueta o categoría a cada intervalo.
- Dos principales tipos:
- Equal Width Binning (EWB): Divide el rango de valores en intervalos de igual tamaño.
- Equal Frequency Binning (EFB): Divide los valores para que cada intervalo contenga el mismo número de observaciones.
Discretización de variables contínuas

Equal Width Binning (EWB)
Bajo EWB, el ancho del intervalo se obtiene de dividir el rango de datos entre el número de intervalos deseados
\[Bin Width = \frac{y_{max}-y_{min}}{\# binds}\] Ventajas:
- Fácil de implementar
- Maneja bien outliers (los coloca en bins separados)
Equal Width Binning (EWB)
Equal Width Binning (EWB)

Equal Frequency Binning (EFB)
Bajo EFB, los datos se dividen en intervalos que contengan la misma cantidad de datos.
Ventajas:
- Maneja outliers al distribuirlos equitativamente
- Asgeura una distribución informe
Equal Frequency Binning (EFB)
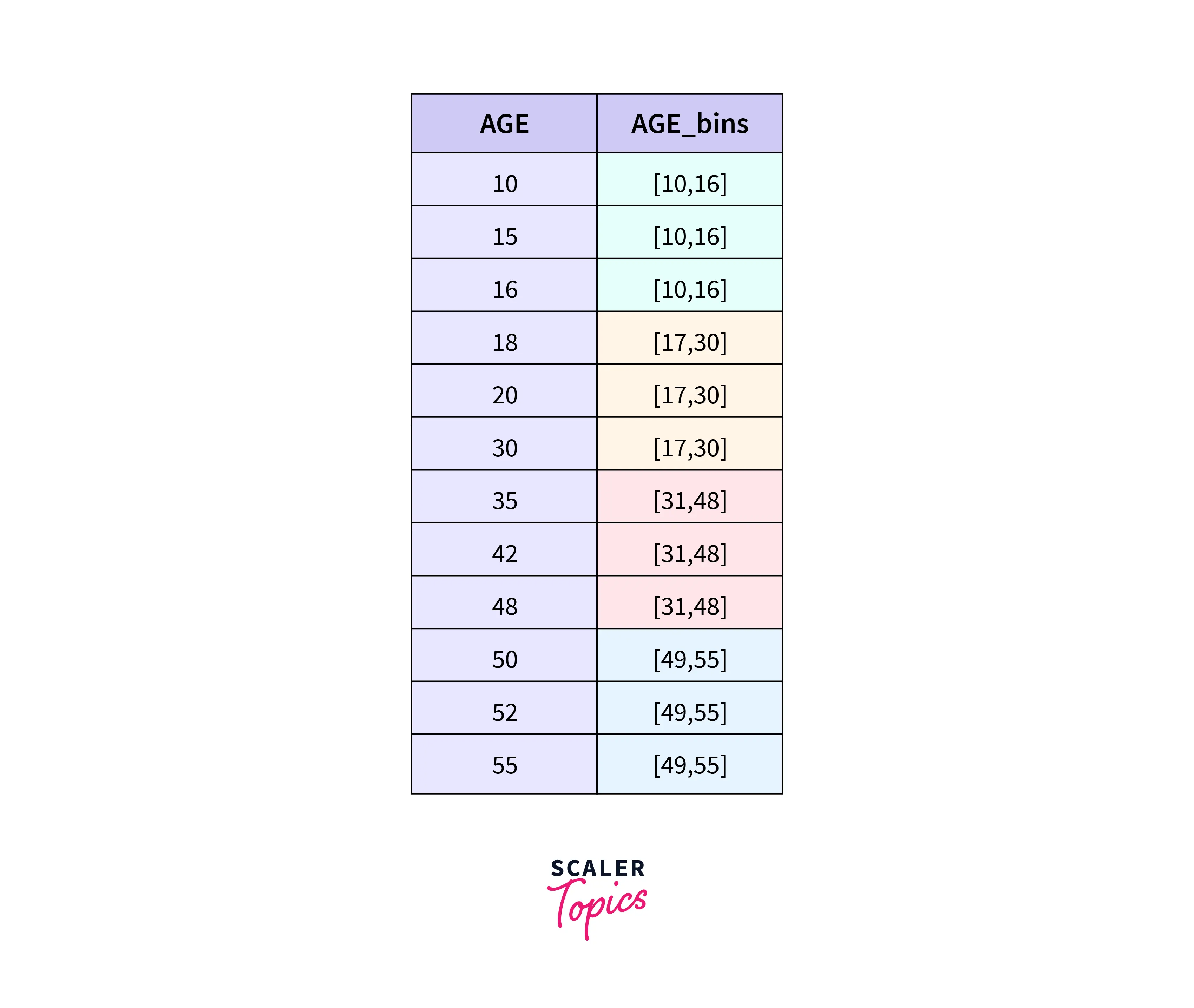
Equal Frequency Binning (EFB)

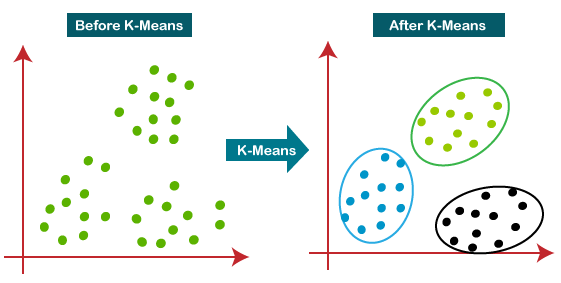
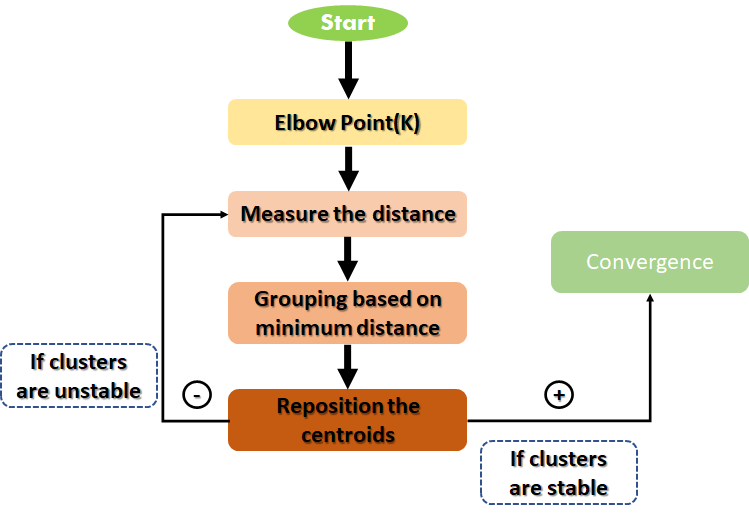
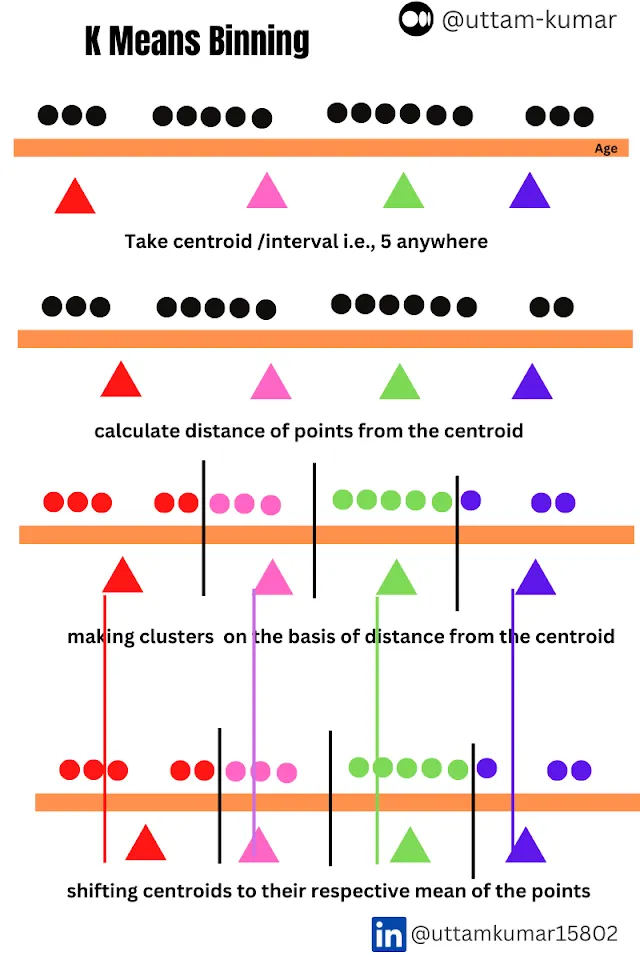
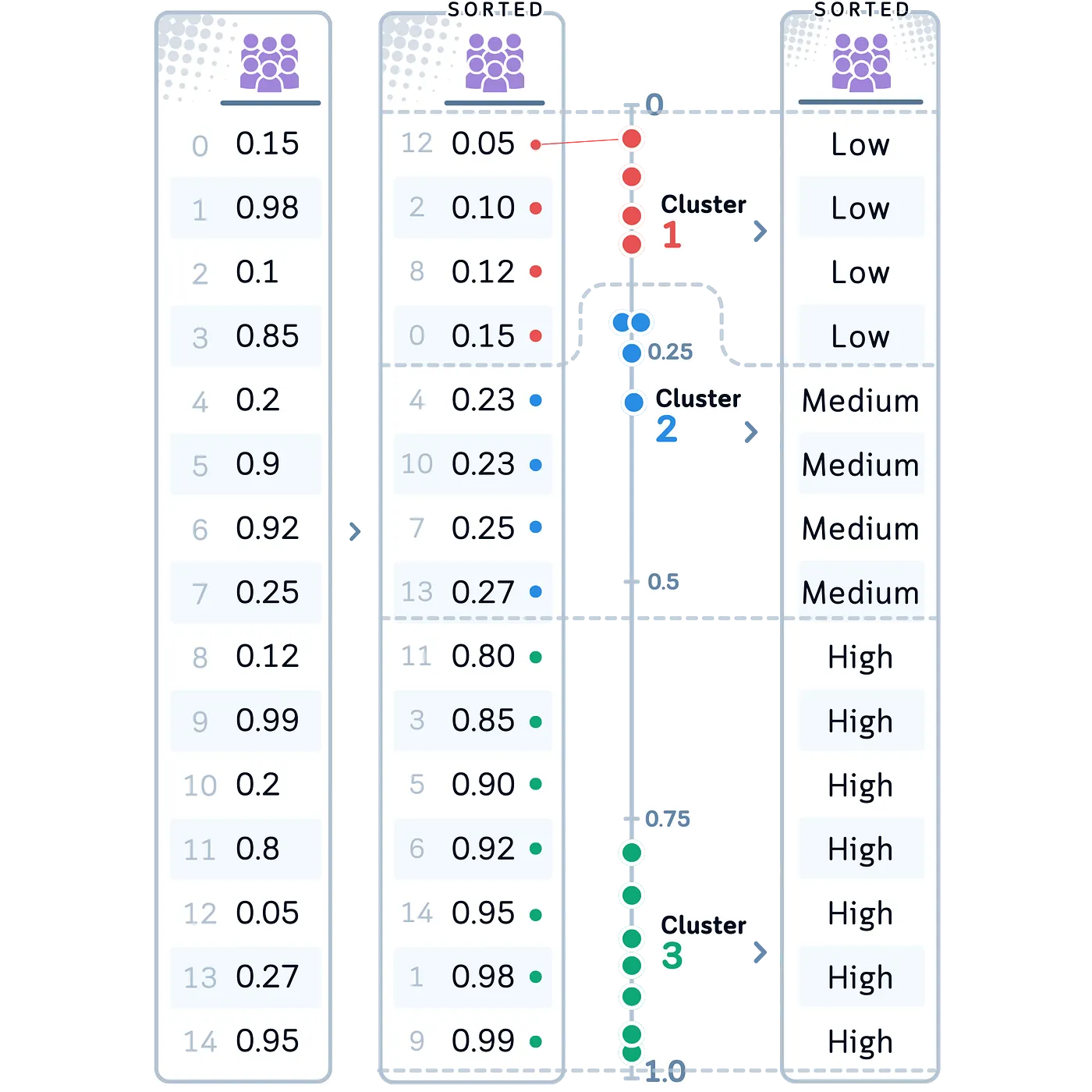
Una más: K-Means Binning
La agrupación de K-means agrupa los datos utilizando el algoritmo de k-means y luego asigna un grupo específico
Ventajas:
- Útil cuando los datos están naturalmente agrupados
- Los bins reflejan agrupaciones naturales en los datos
Una más: K-Means Binning
Una más: K-Means Binning
Una más: K-Means Binning
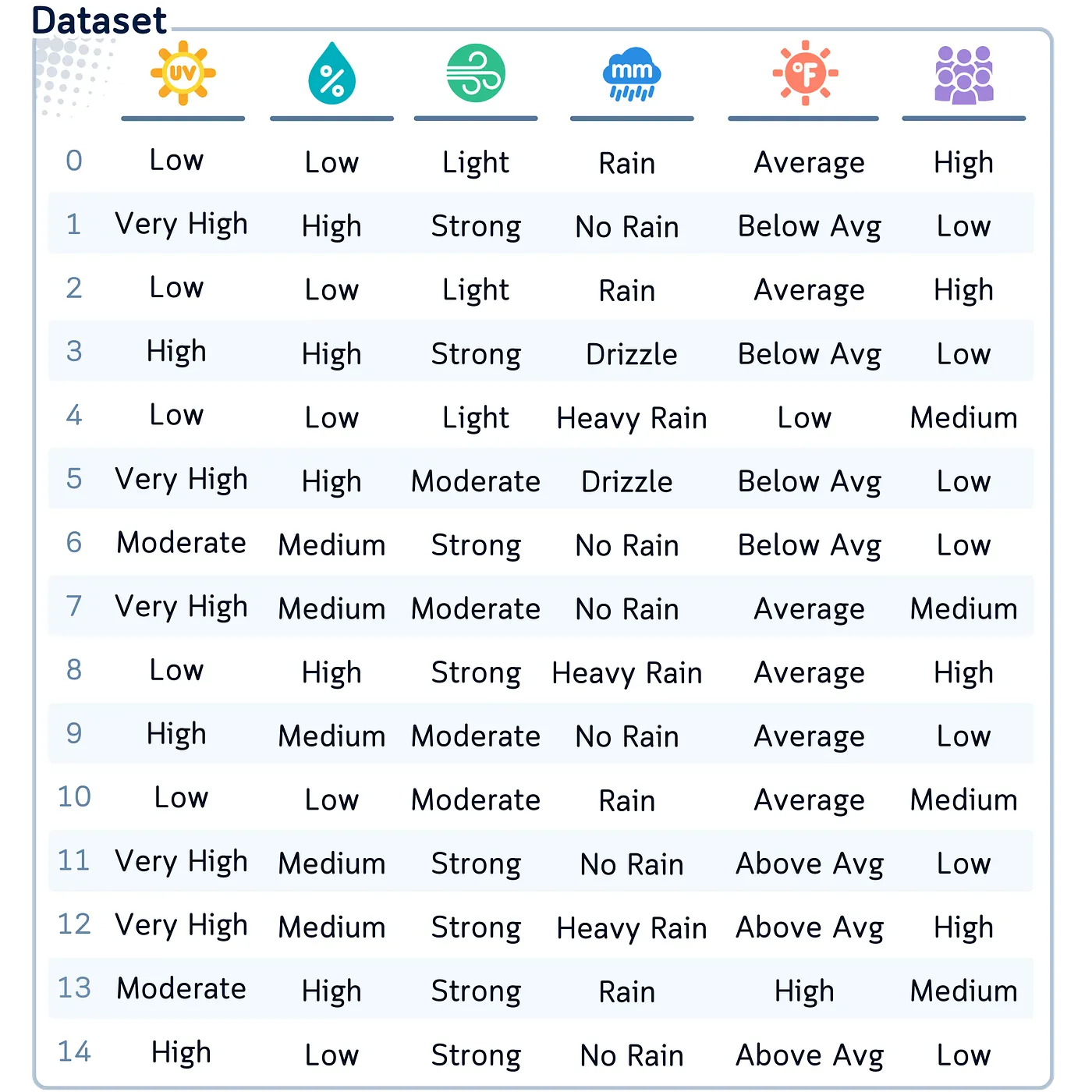
Resumen: Dataset de ejemplo
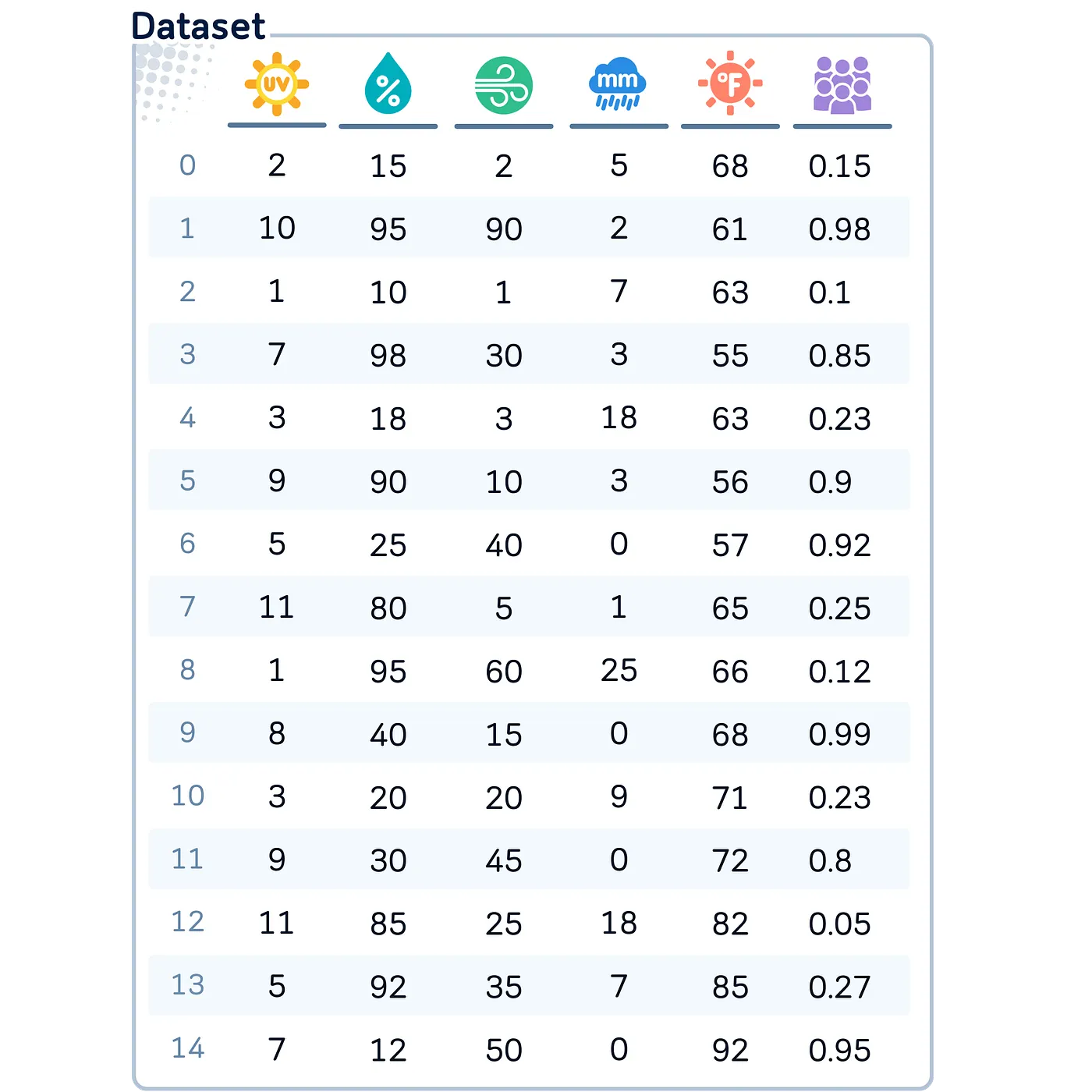
Resumen: Equal-Width Binning
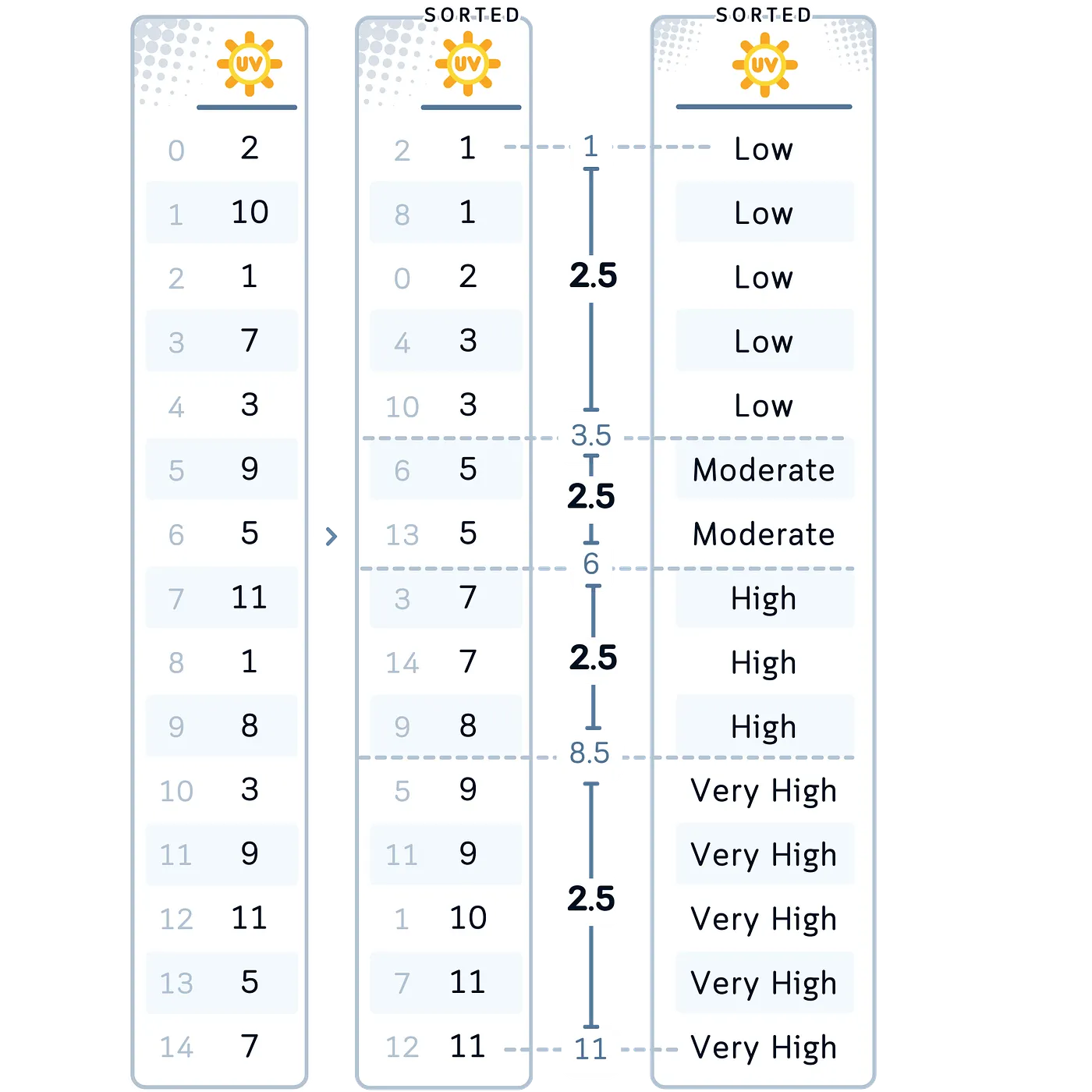
Resumen: Equal-Frequency Binning
Resumen: K Means Binning
Resumen: Logarithmic Binning
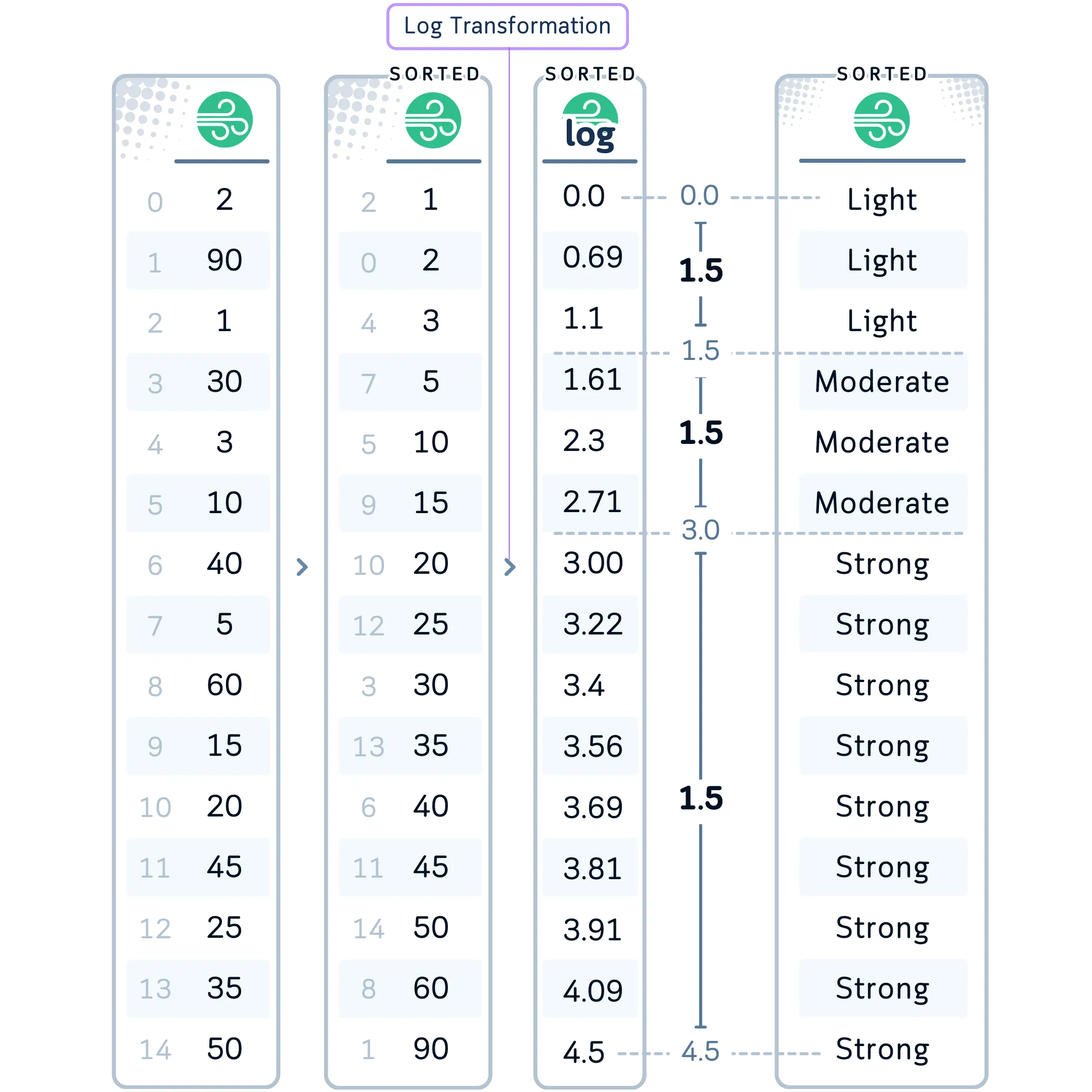
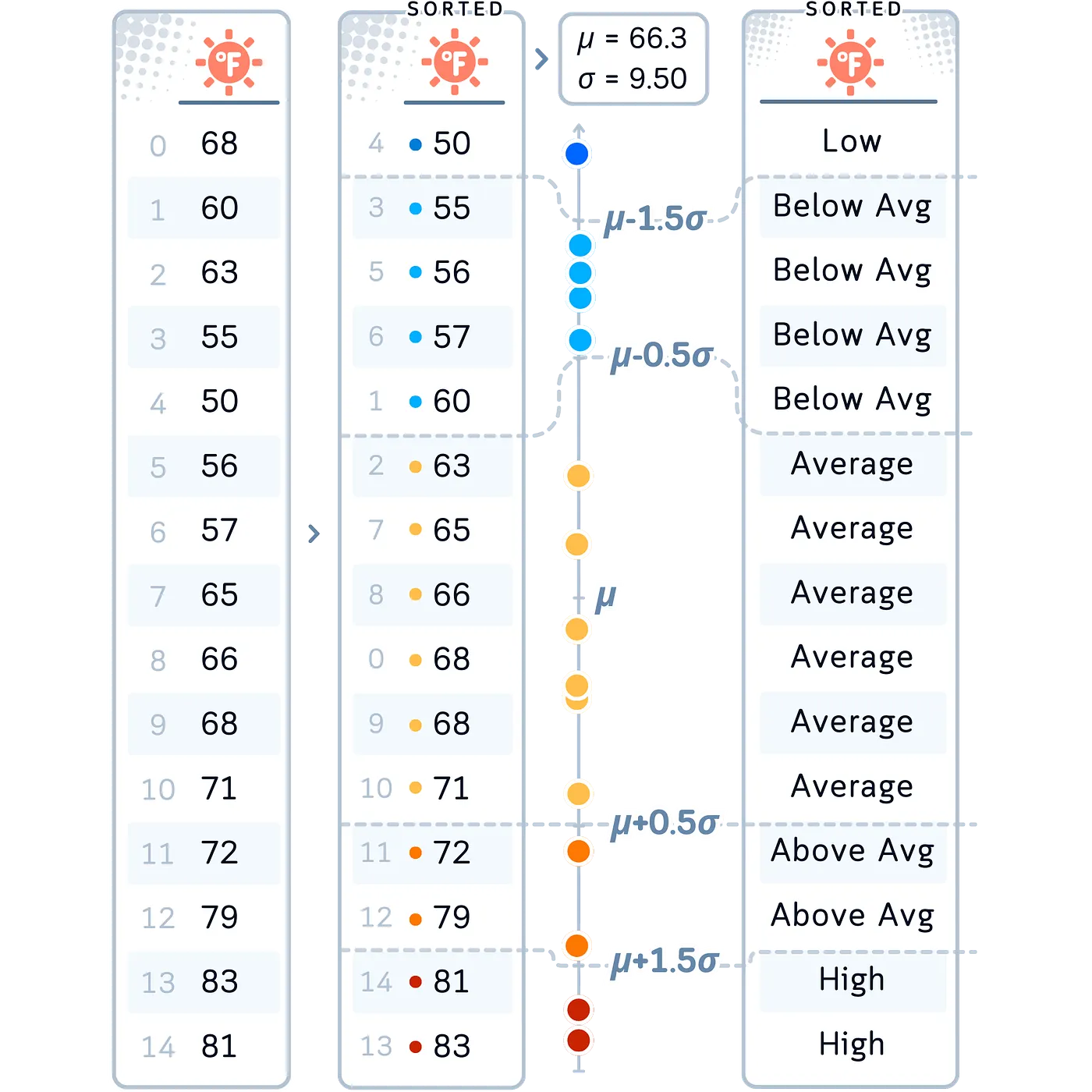
Resumen: Standard Deviation-based Binning
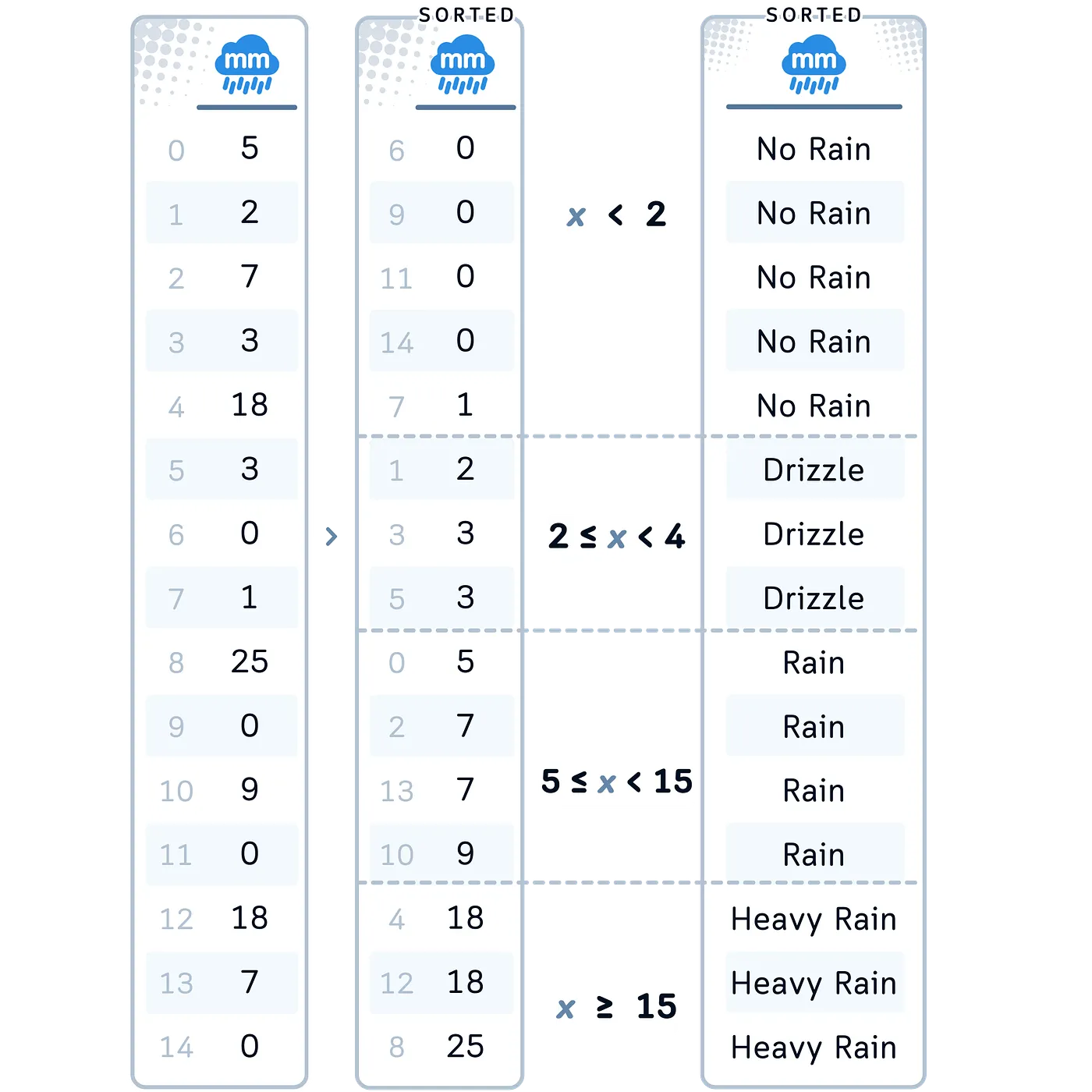
Resumen: Custom Binning
Resumen